No items found.
Released on November 19th, 2025, Segment Anything 3 (SAM 3) is a zero-shot image segmentation model that detects, segments, and tracks objects in images and videos based on concept prompts. This model was developed by Meta as the third model in the Segment Anything series.
Unlike its previous SAM models (Segment Anything and Segment Anything 2), you can provide SAM 3 with the prompt “solar panels” and it will generate precise segmentation masks for all solar panels in an image. SAM 3 generates segmentation masks that correspond to the location of the objects found with a text prompt.
You can try SAM 3 below:
SAM 3 draws precise segmentation masks around the contours of objects that have been identified by a prompt. For example, you can ask SAM 3 to identify a “striped cat” and it will find the striped cats, or you could click on a cat in an image and calculate a segmentation mask that corresponds with the specific cat on which you have clicked:
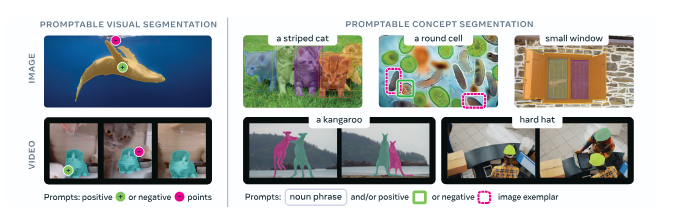
SAM 3 works across images and videos. If you provide a video as an input to SAM 3, the model will track all identified or selected instances of objects through frames in the video. If you provide an image as an input, SAM 3 will run on the input image.
SAM 3 runs at ~30 ms per image on an H200 GPU, handling 100+ objects, but at ~840 M parameters (≈3.4 GB) it remains a server-scale model. For object detection on the edge, you can use SAM-3 to label data and use the labeled data to train a smaller, faster, supervised object detection model. The smaller model will not have text prompting abilities, but would allow you to detect exactly what objects you have trained the model to find in real time.
You can run SAM 3 without fine-tuning. You can also fine-tune SAM 3 to improve its performance on domain-specific tasks. Learn how to fine-tune SAM 3.
SAM 3 builds on architecture from SAM 1, SAM 2, and Perception Encoder.
The SAM 3 architecture is a dual encoder-decoder transformer comprising a DETR-style detector and a SAM 2-inspired tracker that share a unified Perception Encoder (PE). The PE aligns visual features from the image encoder with text and exemplar embeddings from the prompt encoder, creating a joint embedding space for vision-language fusion.
To handle open-vocabulary concepts, the detector adds a global presence head that first determines if the target concept exists in the scene before localizing its instances. This decoupling of recognition (what) and localization (where) significantly improves accuracy on unseen concepts and hard negatives, which are prevalent in natural imagery.
The result is a zero-shot segment-anything engine capable of detecting all matching objects with minimal user input.
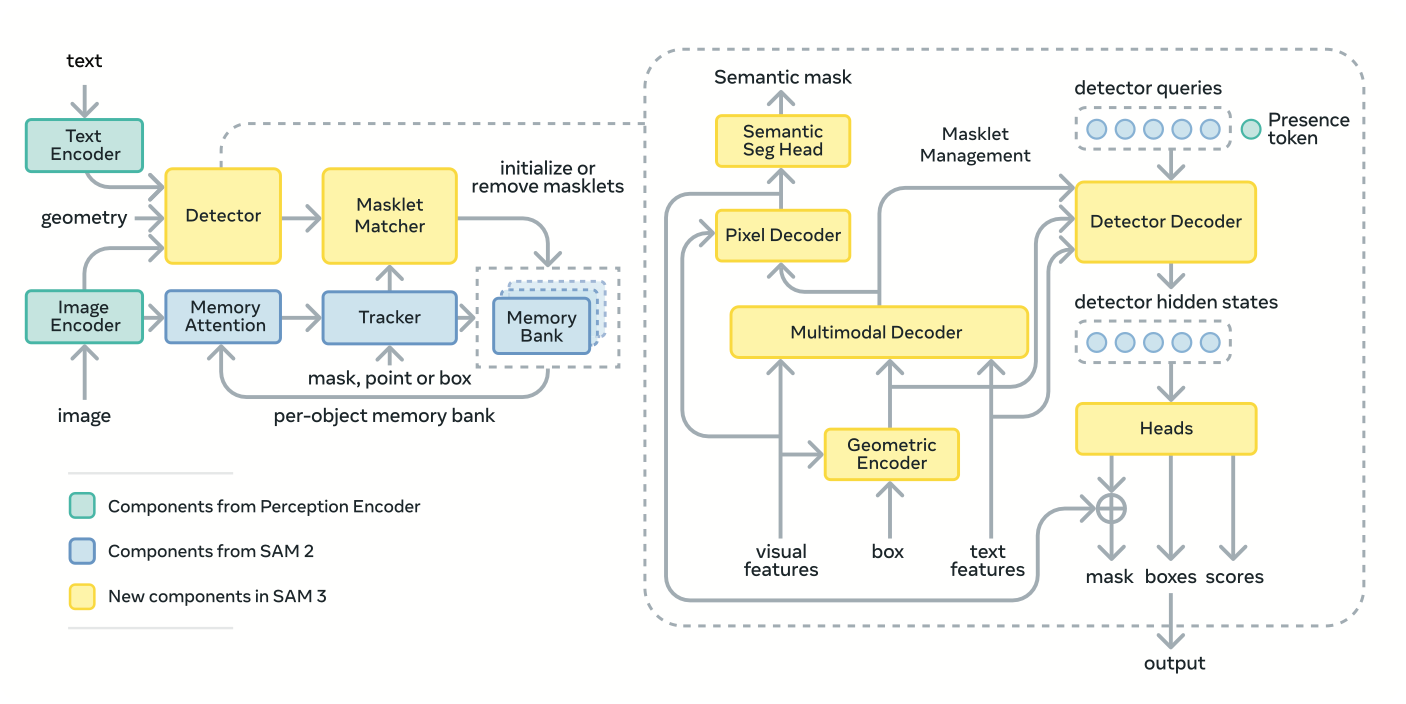
Training occurs in four stages: (1) Perception Encoder pre-training, (2) detector pre-training on synthetic and HQ data, (3) detector fine-tuning on SA-Co HQ, and (4) tracker training with a frozen backbone to stabilize temporal learning.
Segment Anything 3
is licensed under a
Custom
license.
You can use Roboflow Inference to deploy a
Segment Anything 3
API on your hardware. You can deploy the model on CPU (i.e. Raspberry Pi, AI PCs) and GPU devices (i.e. NVIDIA Jetson, NVIDIA T4).
Below are instructions on how to deploy your own model API.
