No items found.
Depth Anything V2 is a state-of-the-art monocular depth estimation model, meaning it can predict depth information from a single image, without needing multiple cameras. It achieves this by training a powerful "teacher" model on synthetic images and then using it to generate pseudo-labels for a large set of real-world unlabeled images. These pseudo-labels are then used to train "student" models, resulting in a model that generalizes well to various scenes and conditions.
You can use Depth-Anything-V2-Small to estimate the depth of objects in images, creating a depth map where:
- Each pixel's value represents its relative distance from the camera
- Lower values (darker colors) indicate closer objects- Higher values (lighter colors) indicate further objects
To learn how to deploy Depth Anything V2, read our deployment guide.
Here is an example of a depth mask from the model:
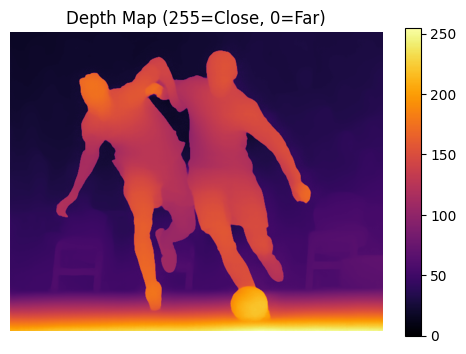
Depth Anything V2
is licensed under a
Apache 2.0
license.
You can use Roboflow Inference to deploy a
Depth Anything V2
API on your hardware. You can deploy the model on CPU (i.e. Raspberry Pi, AI PCs) and GPU devices (i.e. NVIDIA Jetson, NVIDIA T4).
Below are instructions on how to deploy your own model API.
